
Cómo funcionan los algoritmos de machine learning y cuáles son sus aplicaciones prácticas.
El aprendizaje automático se basa en aprender de la experiencia. Al igual que los humanos aprenden de los errores y los aciertos, el aprendizaje automático utiliza datos y algoritmos para crear modelos que van mejorando con el uso y la experiencia.
Los sistemas de aprendizaje automático utilizan los datos de entrenamiento para experimentar y aprender.
Por ejemplo, si queremos que un modelo de aprendizaje automático identifique animales, le mostramos miles de imágenes de perros, vacas, elefantes y más, cada una etiquetada con su nombre correcto.
A partir de estos datos, la máquina comienza a construir un modelo. Este modelo intenta encontrar patrones o características comunes en las imágenes que pueden distinguir cada tipo de animales.
Al principio, el modelo comentará errores. Pero a medida que se experimenta con más imágenes, el modelo se refina y mejora su capacidad para identificar correctamente los tipos de animales.
El proceso de generación de modelos con el aprendizaje automático
El verdadero poder del aprendizaje automático es que al alimentar al modelo con más datos, le permitimos aprender y adaptarse a nuevas situaciones. Este proceso se llama entrenamiento y es necesario para mejorar la precisión del modelo.
Además, a medida que disponemos de más datos, los modelos se ajustan a través de un proceso de validación y prueba, asegurando que funcionen bien en cualquier situación, no solo con los datos con los que fueron entrenados inicialmente.
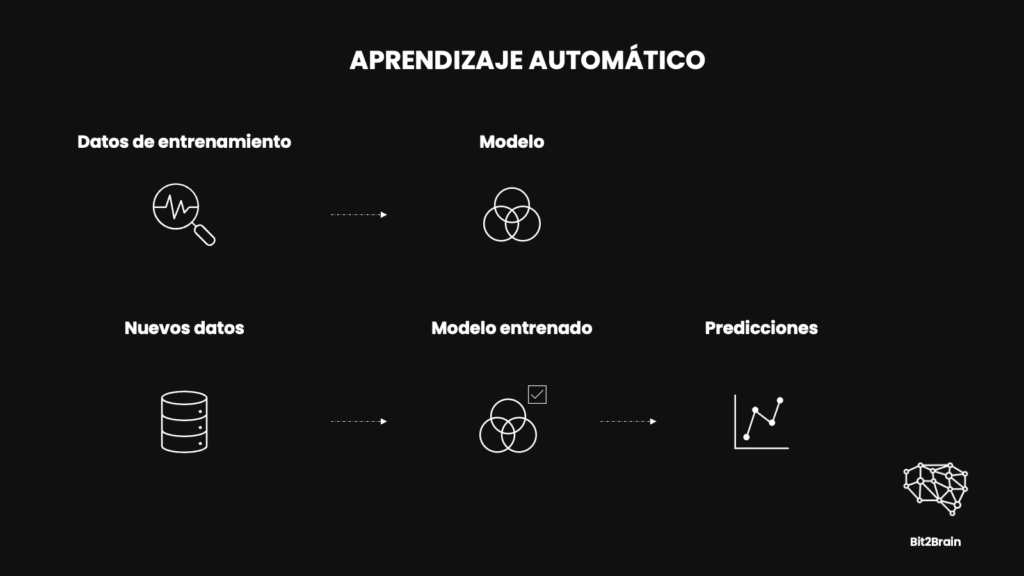
Y esto es exactamente lo que hace que el aprendizaje automático sea tan potente, que puede mejorar continuamente. Con cada nuevo dato de entrenamiento, cada error corregido y cada ajuste al modelo, los modelos se vuelven más inteligentes.
Descubriendo los Tipos de Aprendizaje Automático: Supervisado, No Supervisado y Semisupervisado
El aprendizaje automático se puede categorizar según el tipo de datos que utiliza y cómo aprende de estos para realizar predicciones.

Principalmente, hay tres tipos de aprendizaje automático:
- Supervisado: el modelo se entrena usando un conjunto de datos completamente etiquetado. El modelo tiene una guia para aprender con los datos de entrenamiento etiquetados.
- No supervisado: utiliza datos que no están etiquetados. Esto significa que el modelo debe intentar entender los datos por sí mismo y descubrir patrones o agrupaciones naturales sin referencias externas.
- Semisupervisado: Utiliza una combinación de datos etiquetados y no etiquetados de base. El modelo utiliza los datos etiquetados para aprender un patrón inicial y luego aplica este conocimiento para organizar y entender los datos no etiquetados.
¿Qué es el Aprendizaje Supervisado?
En el aprendizaje supervisado, necesitamos datos etiquetados para entrenar el modelo. Por ejemplo, le proporcionamos al modelo imágenes de perros, vacas y elefantes, cada una claramente etiquetada con su respectiva especie. Acuérdate de cuando eras niño y en la escuela aprendías a clasificar animales con un libro con imágenes y descripciones detalladas de cada uno. Con suficientes ejemplos y correcciones, el modelo aprende a clasificar nuevas imágenes por sí mismo
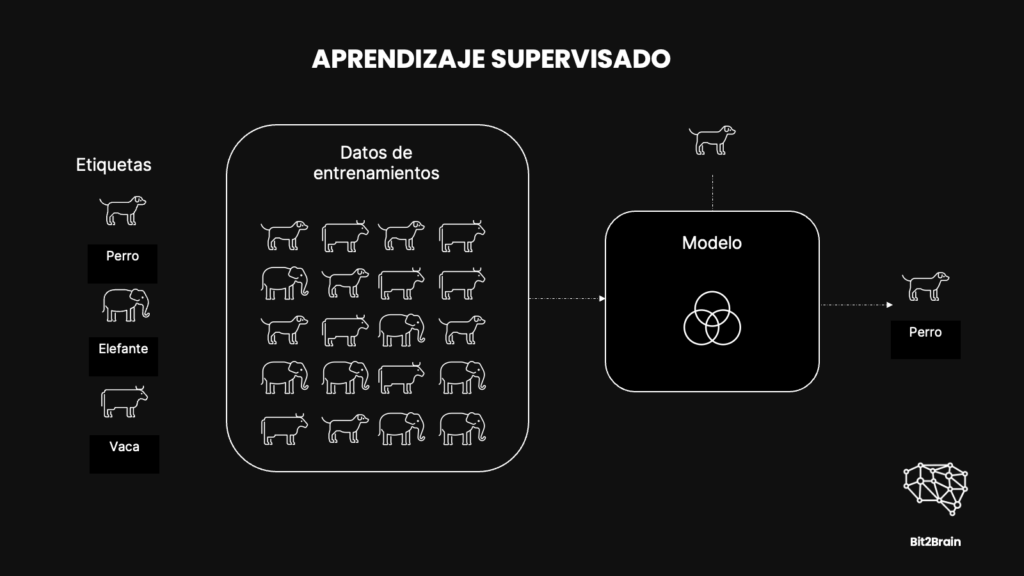
Este método es fundamentalmente un proceso de enseñanza para el modelo, donde se le proporciona una gran cantidad de ejemplos (datos de entrenamiento) que ya tienen respuestas conocidas (etiquetas).
El objetivo es que el modelo aprenda a predecir la etiqueta correcta basándose en estos ejemplos.
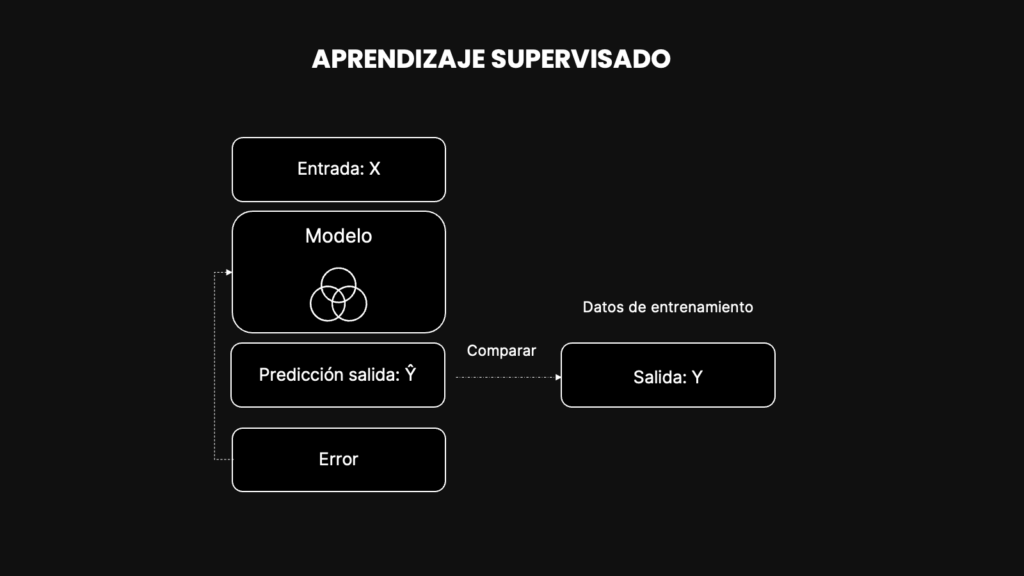
Entendiendo el Proceso de Aprendizaje Supervisado
El aprendizaje supervisado es un ciclo iterativo de predicción, comparación y ajuste, donde el modelo se va refinando progresivamente para mejorar su precisión.
A través de este proceso, el modelo aprende a mapear entradas a salidas, preparándolo para realizar predicciones en situaciones reales.
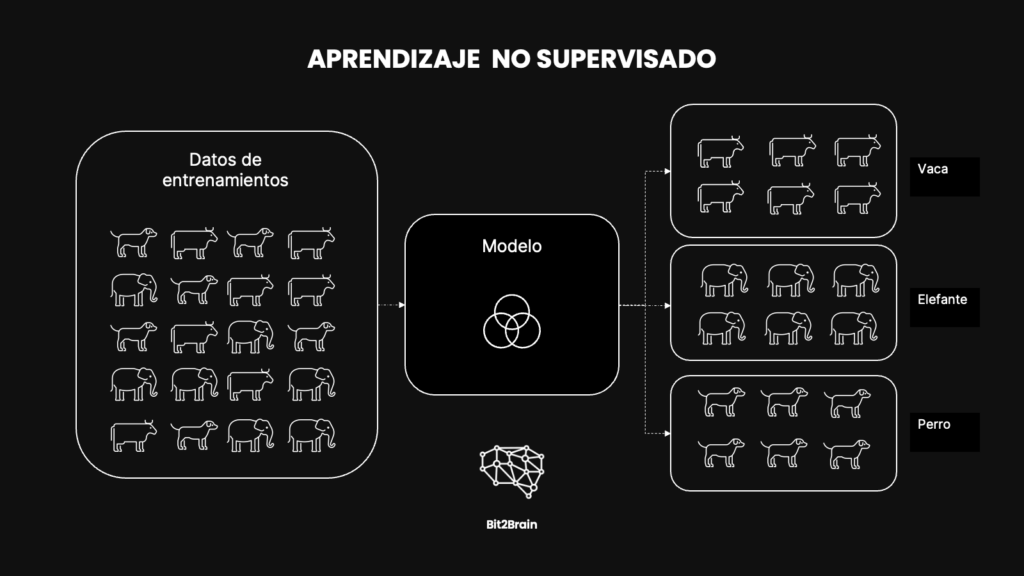
¿Qué es el Aprendizaje No Supervisado?
A diferencia del aprendizaje supervisado, el aprendizaje no supervisado utiliza datos que no están etiquetados. Esto significa que el modelo debe entender los datos por sí mismo y descubrir patrones o agrupaciones naturales sin referencias externas.
Por ejemplo, si tenemos un montón de fotos de perros, vacas y elefantes, el modelo de aprendizaje no supervisado explorará por sí mismo, identificando y comparando características visuales como formas, colores y texturas. Entonces utilizando un proceso llamado clustering, el modelo agrupará las imágenes en diferentes categorías.
Así, sin que nadie le diga explícitamente, el modelo puede formar grupos de imágenes donde, idealmente, todas las fotos de perros estarían en un grupo, todas las de vacas en otro, y todas las de elefantes en otro.
El aprendizaje no supervisado es muy útil cuando no se conoce la estructura subyacente de los datos o cuando es no podemos etiquetar datos a gran escala.
Sin embargo, puede ser más difícil de implementar, ya que los resultados son menos predecibles y pueden requerir una interpretación más subjetiva.
Un ejemplo común de aplicación del aprendizaje no supervisado es la segmentación de clientes en marketing, donde un modelo puede identificar grupos de clientes con comportamientos o preferencias similares sin datos previos sobre las categorías.
Entendiendo el Proceso de Aprendizaje No Supervisado
Paso 1: Recopilación y Preparación de Datos
Usando el ejemplo anterior, el primer paso involucra la recopilación de un conjunto de imágenes que incluya perros, vacas y elefantes.
Estas imágenes no necesitan estar etiquetadas ya que el objetivo del aprendizaje no supervisado es que el modelo descubra por sí mismo las diferencias y similitudes entre las imágenes. Sin embargo, es crucial que las imágenes estén en un formato adecuado y que hayan sido preprocesadas para normalizar su tamaño y resolución, reduciendo así la variabilidad que no aporte al análisis.
Paso 2: Extracción de Características
Antes de poder agrupar las imágenes, el modelo necesita una forma de entender y comparar su contenido. Esto se logra a través de la extracción de características, que puede incluir la identificación de bordes, texturas o colores dominantes. Estas características sirven como la “huella digital” de cada imagen, permitiendo que el modelo compare una imagen con otra.
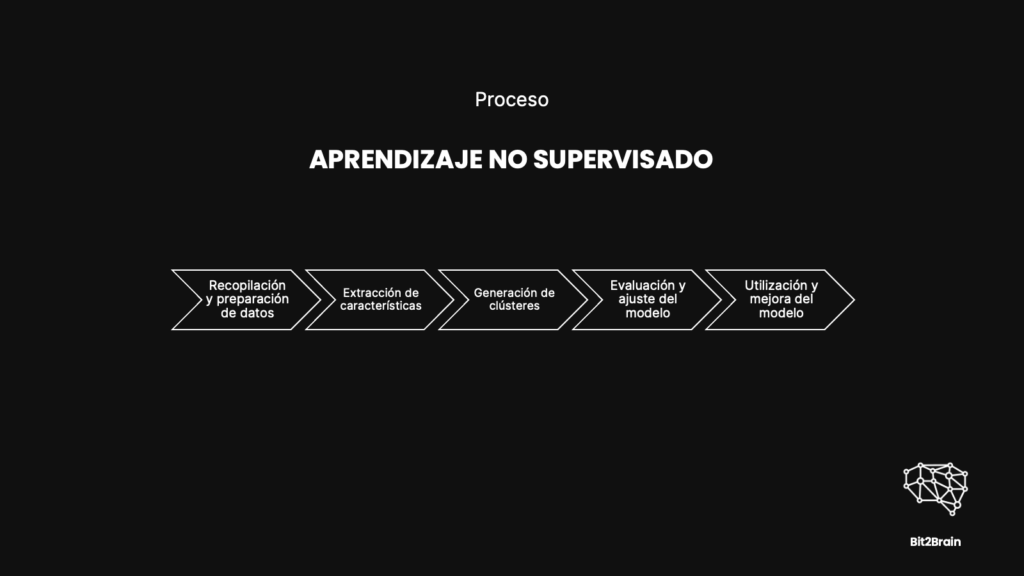
Paso 3: Aplicación de Algoritmos de Clustering
Con las características extraídas, el siguiente paso es aplicar un algoritmo de clustering (agrupamiento). Uno de los más populares es el K-means, que requiere que se defina de antemano el número de clusters (en este caso, tres: perros, vacas y elefantes).
El algoritmo comienza con centroides iniciados al azar y asigna cada imagen al centroide más cercano basado en la similitud de sus características. Luego, recalcula el centroide de cada grupo y repite el proceso varias veces hasta que la asignación de las imágenes a los clusters ya no cambie significativamente.
Paso 4: Evaluación y Ajuste de Clusters
Una vez que las imágenes están agrupadas, es crucial evaluar qué tan bien el modelo ha realizado su tarea. Esto es una dificultad especial del aprendizaje no supervisado, ya que no tenemos etiquetas para verificar si hemos acertado.
Una opción es utilizar la evaluación visual, donde se revisan muestras de imágenes de cada cluster para ver si parecen lógicamente agrupadas. Otra alternativa es utilizar métricas como la silueta, que mide cómo de semejante es una imagen a su propio cluster comparado con otros clusters.
Paso 5: Uso de los Resultados
Los clústers generados pueden ser utilizados de varias maneras, dependiendo de las necesidades del proyecto. Por ejemplo, podrían ayudar en la organización automática de grandes bases de datos de imágenes, en la mejora de sistemas de recomendación o incluso en la identificación de imágenes atípicas que no encajan claramente en ninguno de los grupos conocidos.
¿Qué es el Aprendizaje Semisupervisado?
El aprendizaje semisupervisado es una mezcla entre los enfoques supervisado y no supervisado. Utiliza una combinación de datos etiquetados y no etiquetados, lo que puede ser útil cuando los datos etiquetados son limitados.
En este tipo de aprendizaje, el modelo utiliza los datos etiquetados para aprender un patrón inicial y luego aplica este conocimiento para organizar y entender los datos no etiquetados.
Aquí te explico cómo funcionaría este modelo para el ejemplo anterior donde identificábamos imágenes de perros, vacas y elefantes.
Comenzamos con una pequeña cantidad de imágenes etiquetadas.

Por ejemplo, podríamos tener unas decenas de fotos que sabemos con seguridad que son de perros, vacas y elefantes.
Estas imágenes etiquetadas sirven como guía para el modelo, ayudándolo a aprender características clave que distinguen a cada tipo de animal.
A continuación, introducimos una gran cantidad de imágenes no etiquetadas. El modelo utiliza lo que ha aprendido de las imágenes etiquetadas para intentar identificar y categorizar estas nuevas imágenes.
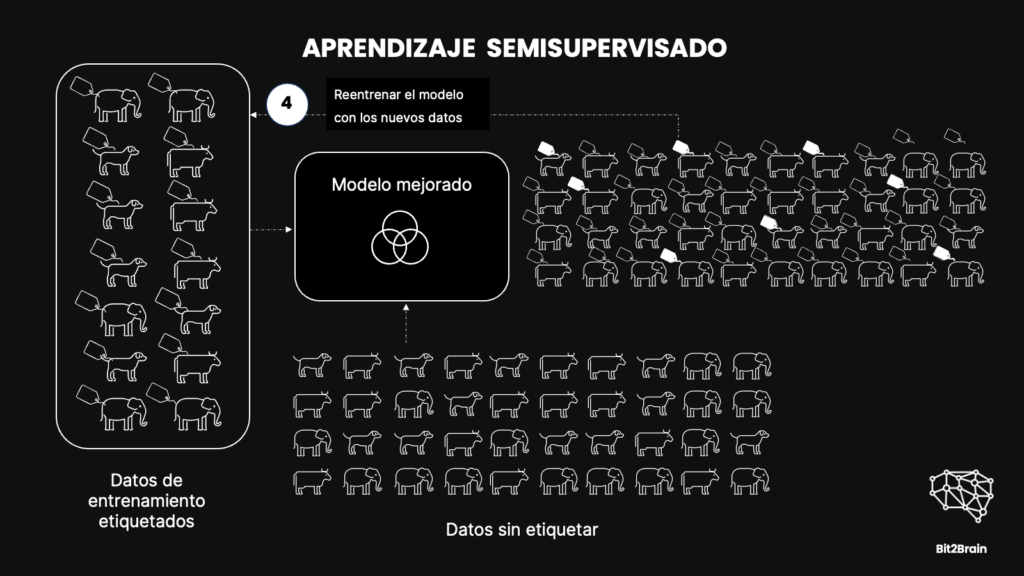
El objetivo del aprendizaje semisupervisado es aprovechar tanto las pequeñas cantidades de datos etiquetados para guiar el aprendizaje, como los grandes volúmenes de datos no etiquetados para mejorar la generalización del modelo
Entendiendo el Proceso de Aprendizaje Semisupervisado
El aprendizaje semisupervisado es especialmente útil en situaciones donde los datos etiquetados son difíciles de obtener, pero tenemos muchos datos no etiquetados.
Siguiendo con el ejemplo anterior, imaginemos que contamos con un total de 10,000 imágenes, de las cuales solo 1,000 están etiquetadas. El proceso de generación del modelo sería el siguiente:
Paso 1: Entrenar al modelo con datos etiquetados
Inicialmente, utilizamos las 1,000 imágenes etiquetadas para entrenar un modelo básico de clasificación. Con estos datos, el modelo aprende a identificar características visuales específicas de perros, vacas y elefantes. El entrenamiento con estos datos etiquetados establece una base preliminar sobre la cual el modelo puede identificar características generales de cada animal.
Por ejemplo, podríamos tener unas decenas de fotos que sabemos con seguridad que son de perros, vacas y elefantes.
Estas imágenes etiquetadas sirven como guía para el modelo, ayudándolo a aprender características clave que distinguen a cada tipo de animal.
A continuación, introducimos una gran cantidad de imágenes no etiquetadas. El modelo utiliza lo que ha aprendido de las imágenes etiquetadas para intentar identificar y categorizar estas nuevas imágenes.
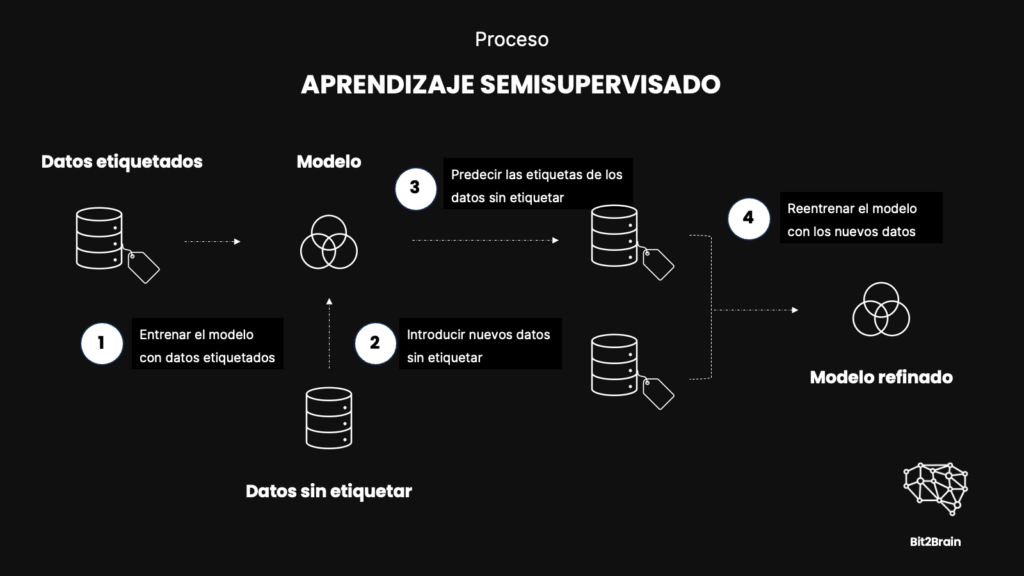
Paso 2: Aplicación del Modelo a Datos No Etiquetados
Una vez que el modelo inicial ha sido entrenado con los datos etiquetados, el siguiente paso es aplicarlo al resto de las 9,000 imágenes no etiquetadas. Aquí, el modelo utiliza lo que ha aprendido sobre las características de cada tipo de animal para hacer predicciones tentativas sobre la categoría de cada imagen no etiquetada.
Paso 3: Refinamiento Mediante Pseudoetiquetado
Una técnica común en aprendizaje semisupervisado es el pseudoetiquetado. Este proceso implica que las predicciones hechas por el modelo en los datos no etiquetados se utilizan como si fueran etiquetas verdaderas para un nuevo ciclo de entrenamiento.
Solo se seleccionan aquellas predicciones en las que el modelo tiene alta confianza. Reentrenamos el modelo con este nuevo conjunto de datos, que ahora incluye las etiquetas originales y las pseudoetiquetas. Este proceso ayuda a mejorar la capacidad del modelo para generalizar a partir de los datos no etiquetados, refinando su precisión y efectividad.
Paso 4: Validación y Ajustes Finales
Finalmente, para asegurar la validez del modelo, se realiza una validación cruzada utilizando un subconjunto separado de imágenes que nunca se usaron durante el entrenamiento. Esto nos permite evaluar la precisión del modelo en datos completamente nuevos y realizar ajustes finales para mejorar su rendimiento.
Ejemplos de aprendizaje supervisado, semisupervisado y no supervisado
Ahora que ya entendemos un poco mejor los distintos tipos de aprendizaje automático, Vamos a explorar algunos ejemplos concretos de cómo se utilizan los tres tipos principales de aprendizaje automático: supervisado, no supervisado y semisupervisado.
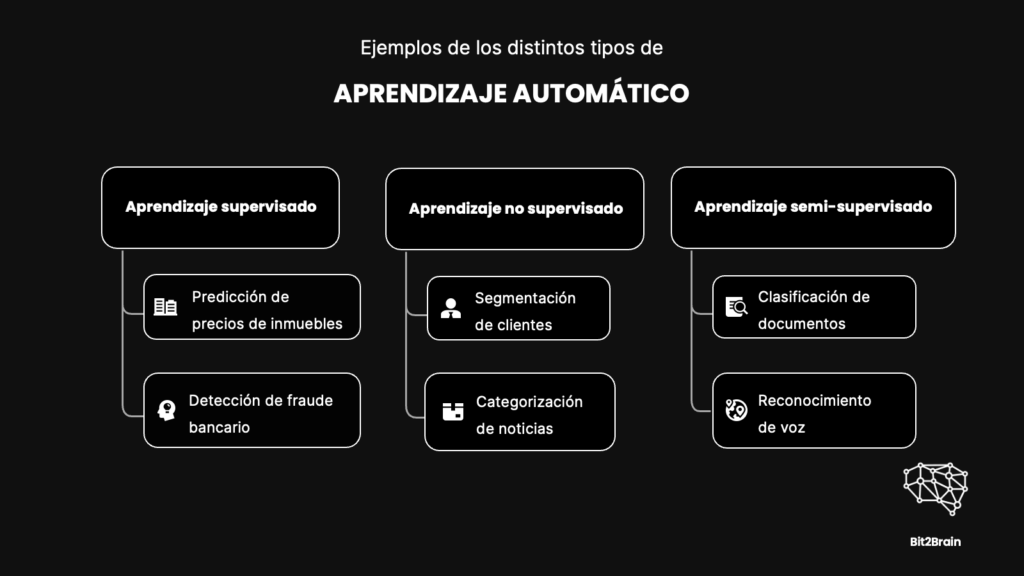
Ejemplos de Aprendizaje Supervisado:
- Predicción de precios de inmuebles:
Utilizando datos históricos sobre las ventas de inmuebles, que incluyen características como la ubicación, el tamaño, el año de construcción y el precio de venta, los modelos de aprendizaje supervisado pueden predecir los precios de propiedades similares. Este modelo ayuda a los inversores, compradores y vendedores a tomar decisiones informadas basadas en tendencias y patrones del mercado.
- Detección de fraude bancario:
Los sistemas bancarios emplean algoritmos de aprendizaje supervisado para identificar actividades sospechosas que podrían indicar fraude. Al analizar transacciones pasadas etiquetadas como fraudulentas o no fraudulentas, estos modelos aprenden a detectar señales de alerta en nuevas transacciones, contribuyendo a la prevención del fraude y protegiendo a los usuarios de pérdidas financieras.
Ejemplos de Aprendizaje No Supervisado:
- Segmentación de clientes:
Las empresas utilizan técnicas de aprendizaje no supervisado para segmentar a los clientes en grupos basados en comportamientos de compra, preferencias y otros factores demográficos. Esta segmentación permite a las empresas desarrollar estrategias de marketing más dirigidas y personalizadas, mejorando la satisfacción del cliente y aumentando la eficacia de sus campañas.
- Categorización de noticias:
Los algoritmos de aprendizaje no supervisado pueden organizar automáticamente grandes volúmenes de artículos de noticias en categorías temáticas sin necesidad de etiquetas previas. Esto no solo ayuda a los lectores a encontrar noticias de su interés más rápidamente, sino que también apoya a los editores en la gestión y distribución de contenido.
Ejemplos de Aprendizaje Semisupervisado:
- Clasificación de documentos:
En entornos donde solo algunos documentos están etiquetados, como puede ser en archivos legales o académicos, los modelos semisupervisados utilizan estas etiquetas limitadas junto con un gran volumen de documentos no etiquetados para mejorar su capacidad de clasificación. Esto es especialmente útil para organizar bibliotecas digitales y facilitar la recuperación de información.
- Reconocimiento de voz:
Los sistemas de reconocimiento de voz se benefician del aprendizaje semisupervisado al utilizar un pequeño conjunto de datos de voz etiquetados junto con una cantidad mucho mayor de grabaciones no etiquetadas. Estos modelos mejoran la capacidad del sistema para entender diferentes acentos, dialectos y variaciones en la pronunciación, haciendo que los asistentes de voz y otros sistemas interactivos sean más precisos y accesibles para una gama más amplia de usuarios.
Conclusión
Cada tipo de aprendizaje automático tiene sus características propias, y la elección entre aprendizaje supervisado, no supervisado y semisupervisado depende en gran medida de la naturaleza de los datos disponibles y de los objetivos específicos del proyecto.
Comprender las diferencias entre el aprendizaje supervisado, no supervisado y semisupervisado es crucial para seleccionar el planteamiento adecuado para maximizar la efectividad del modelo en tareas de predicción o clasificación.