
¿Alguna vez te has preguntado cómo tu teléfono puede reconocer tu cara o cómo Netflix sabe las series que te gustan y qué puede recomendarte?
La respuesta está en los Modelos de Machine Learning (aprendizaje automático).
En este artículo, “Modelos Machine Learning para dummies: Guia completa”, vamos a desgranar los modelos de Machine Learning, para que entiendas cómo se crean, validan y despliegan.
¿Qué es un Modelo Machine Learning?
Un modelo de Machine Learning es un programa computacional diseñado para reconocer patrones en los datos y hacer predicciones basadas en ellos.
Estos modelos se crean a partir de algoritmos de Machine Learning, que se entrenan con datos etiquetados (supervisados), no etiquetados (no supervisados) o una combinación de ambos (semi-supervisados).
Tipos de Modelos de Machine Learning
Vamos a repasar los tipos de modelos de aprendizaje automático que explicamos en el blog “Explorando el aprendizaje automático”.

1. Modelos Supervisados
Los modelos supervisados se entrenan con datos etiquetados, es decir, cada ejemplo de entrenamiento incluye la entrada y el resultado deseado. Se utilizan principalmente para tareas de clasificación y regresión.
2. Modelos No Supervisados
Los modelos no supervisados se entrenan con datos no etiquetados. El algoritmo busca patrones o estructuras ocultas en los datos.
3. Modelos Semisupervisados
Los modelos semisupervisados combinan una pequeña cantidad de datos etiquetados con una gran cantidad de datos no etiquetados durante el entrenamiento.
¿Cuál es la diferencia entre un Modelo y un algoritmo de Machine Learning?
Aunque frecuentemente se habla de algoritmos y modelos de aprendizaje automático de manera intercambiable, en realidad no son exactamente lo mismo. Para entender la diferencia, vamos a ponernos el gorro de cocineros.
¿Qué es un algoritmo de Machine Learning?
Piensa en un algoritmo de machine learning como una receta de cocina. Esta receta te dice paso a paso cómo preparar, por ejemplo, un pastel. La receta en sí no es el pastel. Es solo una serie de instrucciones que, si las sigues, te permitirán hornear un pastel.
Modelos de Machine Learning
Ahora, imagina que sigues la receta y cocinas un pastel. El pastel es el resultado final de seguir la receta. En el caso del machine learning, el modelo es el resultado final de entrenar el algoritmo con datos.
Diferencia Clave entre algoritmos y modelos de machine learning:
- Algoritmo de Machine Learning: Es la receta, es decir, el conjunto de instrucciones o pasos que debes seguir para resolver un problema utilizando datos.
- Modelo de Machine Learning: Es el pastel, es decir, el resultado final que obtienes después de seguir la receta y entrenar el algoritmo con datos.
Proceso de generación de Modelos de Machine Learning
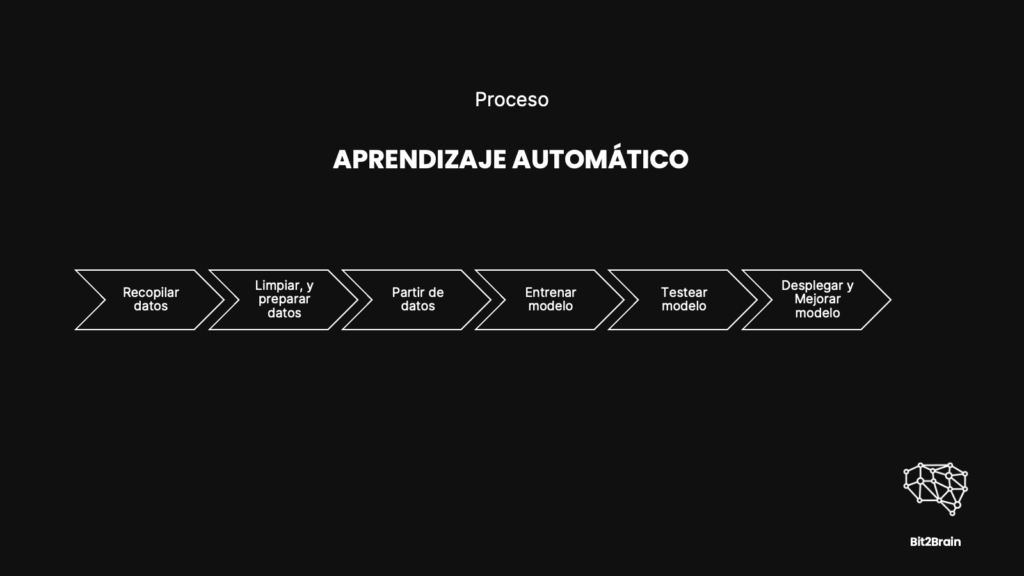
1. Recopilar los Datos
Primero, necesitas recopilar datos relevantes para tu problema. Los datos son la materia prima para entrenar modelos.
Los datos pueden provenir de distintas fuentes como bases de datos, sensores, tablas de Excel, archivos CSV, APIs, etc.
Por ejemplo, si quieres predecir los precios de las casas, necesitarás datos sobre diferentes casas y sus precios.
2. Limpiar y preparar los datos
Antes de usar los datos, debes asegurarte de que estén limpios y en un formato adecuado. Este proceso incluye eliminar datos incorrectos o vacíos, convertir y normalizar valores para asegurar que el modelo funcione.
También implica unificar el formato, convirtiendo los datos a un formato que el modelo pueda entender. Por ejemplo, unificar formatos de fecha, convertir textos a números y asegurarte de que las columnas numéricas realmente contengan números.
En este paso, también es importante y unificar unidades de medida para mantener la consistencia. Por ejemplo, para un atributo que puede ser altura, unificar unidades significaría convertir todas las alturas a centímetros.
3. Partir los datos
Con los datos limpios, procedemos a partir el set de datos para crear el modelo de Machine Learning. Generalmente, la partición de datos se realiza en dos: datos de entrenamiento y datos de testeo.
- Datos de Entrenamiento: Se utilizan para entrenar al modelo y suelen representar el 70-80% de los datos totales. El modelo aprende a partir de estos datos encontrando patrones y relaciones. La calidad y cantidad de estos datos está directamente relacionada con la precisión del algoritmo: a datos más diversos y de mejor calidad, mejor y más rápido aprenderá el algoritmo.
- Datos de Testeo: Después de entrenar el modelo con los datos de entrenamiento, se evalúa utilizando los datos de testeo. Los datos de testeo representan el 20 -30% de los datos totales y permiten verificar si el modelo funciona, utilizando datos distintos, datos que no ha visto antes. Este proceso de validación ayuda a medir la precisión del modelo y a asegurarse de que no solo memoriza los datos de entrenamiento sino que también puede generalizar y hacer predicciones correctas sobre nuevos datos. Si el modelo funciona bien con los datos de testeo, es una señal de que está listo para ser usado con datos reales.
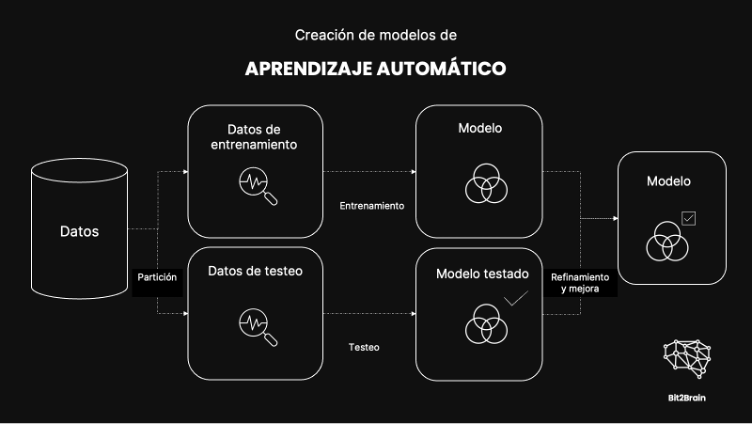
4. Seleccionar el algoritmo y entrenar al modelo
Con los datos ya partidos, se selecciona el algoritmo que mejor se adapte al problema y se le enseña utilizando los datos de entrenamiento. Durante este proceso el algoritmo busca patrones y relaciones entre los datos de entrenamiento y ajusta sus parámetros para aprender a hacer predicciones o clasificaciones correctas.
Este ajuste se realiza repetidamente, revisando cómo funciona el algoritmo y mejorando con cada iteración para minimizar los errores.
Durante el entrenamiento, es importante evitar que el modelo se ajuste demasiado a los datos de entrenamiento, lo que se conoce como sobreajuste. Esto significa que el modelo se vuelve demasiado bueno en predecir resultados con los datos de entrenamiento pero falla con datos nuevos.
Para evitarlo, se utilizan técnicas como la validación cruzada y la regularización, que ayudan a asegurar que el modelo no solo aprenda bien de los datos de entrenamiento, sino que también pueda manejar datos nuevos de manera efectiva.
5. Testear y validar el modelo
Después de entrenar el modelo, toca probarlo para evaluar si funciona. En este paso se utilizan los datos de testeo o de prueba. El modelo no ha visto todavía estos datos durante el entrenamiento,y con ellos se puede medir cómo de bien funciona el modelo.
Para probar el modelo, se utilizan varias métricas de evaluación que varían según el tipo de problema. Estas métricas proporcionan información detallada sobre el rendimiento del modelo, destacando sus fortalezas y debilidades en diferentes aspectos.
La validación del modelo también puede incluir técnicas como la validación cruzada, donde los datos se dividen en múltiples subconjuntos y el modelo se entrena y prueba varias veces.
Este enfoque ayuda a asegurarse de que el modelo sea robusto y no esté simplemente ajustado a unos datos específicos. Validar de esta manera proporciona una evaluación más robusta, asegurando que esté listo para su implementación en un entorno real.
En esta fase cuando los modelos machine learning no funcionan tan bien como se espera, se realizan ajustes para mejorar su rendimiento, como ajustar los parámetros del algoritmo, añadir más datos de entrenamiento o volver al comienzo y limpiar y formatear mejor los datos.
6. Desplegar el modelo
Finalmente, con el modelo de machine learning entrenado y validado, es hora de desplegarlo en un entorno real.
Desplegar el modelo implica integrar el modelo entrenado en una aplicación o sistema que interactúe con los usuarios o con otros sistemas de software.
Después del despliegue, el trabajo no termina. Monitorizar continuamente el rendimiento del modelo es fundamental para asegurar que sigue funcionando bien con datos nuevos de uso. A veces, después de un tiempo de utilización se recolectan nuevos datos para volver a entrenar y mejorar el modelo.
El mantenimiento continuo del modelo garantiza que siga proporcionando valor y ayudando a tomar decisiones basadas en datos de manera efectiva.
Creación de modelos de Machine Learning: la importancia de los datos, los algoritmos y el proceso
Crear modelos de Machine Learning requiere un entendimiento claro de los datos, los algoritmos y el proceso para generar el modelo efectivamente.
Espero que este blog haya aclarado algunos de los conceptos fundamentales y te motive a seguir formándote y aprender acerca de los modelos de machine learning.