
Alojar tu propio modelo abierto o utilizar modelos cerrados a través de API
Introducción
Con el reciente lanzamiento de los modelos de lenguaje Llama 3 de código abierto por parte de Meta, muchas empresas se encuentran debatiendo cuál es la mejor manera de aprovechar esta poderosa tecnología de IA. Y es que nos encontramos en el primer momento en el que existe un modelo abierto (gratuito) con un rendimiento comparable a Claude 3 Sonnet y ciertamente muy superior a GPT3.5, el modelo que nos dejó boquiabiertos a finales de 2022.
Meta ha lanzado dos versiones de Llama 3: un modelo de 8 mil millones de parámetros y otro más potente de 70 mil millones de parámetros. En este post, nos centraremos en el modelo de 70b y analizaremos las ventajas y desventajas de alojar internamente este modelo en comparación con utilizar modelos cerrados disponibles a través de APIs de compañías consolidadas como OpenAI y Anthropic.
Uso de modelos cerrados mediante API
Seguramente hallas interaccionado con ChatGPT mediante su web. Quizás incluso hallas usado otros modelos de lenguaje. Si quieres empaquetar estas herramientas en una solución comercial, o utilizarla en una existente, el siguiente paso es el acceso mediante API. Esto permite automatizar el proceso de pregunta-respuesta, sin necesidad de usar navegador web. Eso sí, tendrás que pagar por cada consulta que hagas. Esta es la opción más extendida en empresas que utilizan IA generativa, al menos hasta el momento. Los beneficios de esta técnica son:
- Facilidad de uso y rapidez de implementación: No necesitas preocuparte por configurar servidores, instalar software o mantener la infraestructura. Solo te conectas a la API y comienzas a hacer requests al modelo de inmediato. Esto puede ahorrar una enorme cantidad de tiempo y esfuerzo, especialmente si no cuentas con un equipo técnico dedicado.
- Escalabilidad y confiabilidad: Los proveedores gestionan toda la escalabilidad y confiabilidad por ti. Si de repente experimentas picos en el uso del modelo, la API podrá manejarlos sin problemas. Con tu propia instalación, tendrías que asegurarte proactivamente de tener suficiente capacidad de cómputo para manejar los picos de demanda. Además, los proveedores de API generalmente garantizan altos niveles de disponibilidad, por lo que no tienes que preocuparte por tiempo de inactividad.
- Acceso a los últimos modelos: Compañías como OpenAI y Anthropic están a la vanguardia de la investigación y desarrollo de IA, lanzando continuamente modelos más potentes y capaces. Al utilizar sus APIs, siempre tendrás acceso a sus modelos más recientes, como GPT-4 o Claude 3 Opus, sin tener que preocuparte por actualizar o reentrenar tus propios modelos.
Alojando tu propio modelo
Como se comentaba anteriormente, estamos en el primer momento de la historia en el que tenemos disponible un modelo abierto (Llama 3) de alto rendimiento. Entonces, ¿por qué no usarlos simplemente de forma gratuita? Puedes hacerlo, pero deberás invertir previamente en la arquitectura necesaria (es decir, un ordenador potente). Si lo haces, alojar internamente tu propia instancia de Llama 3 puede tener mucho sentido, especialmente por las siguientes razones:
- Fija los gastos: Una vez que hayas configurado tu modelo Llama 3, tendrás un costo fijo de infraestructura, sin importar cuánto lo utilices. Si planeas un uso intensivo del modelo, como en aplicaciones de servicio al cliente o procesamiento de lenguaje a gran escala, alojar tu propio Llama 3 podría ser más económico a largo plazo que pagar por cada llamada a una API externa.
- Eliminación de la “fricción mental” en el uso del modelo: Cuando se utilizan modelos de lenguaje a través de APIs, surge una constante “fricción mental” en torno al costo por consulta, donde debes evaluar constantemente si vale la pena el gasto o si debieses buscar una alternativa más barata. Sin embargo, al alojar tu propio Llama 3, este costo por consulta desaparece esencialmente, liberándote para utilizar el modelo tan a menudo como quieras sin la carga cognitiva de evaluar el ROI de cada solicitud, lo que puede conducir a un uso más creativo y experimental, permitiendo flujos de trabajo más fluidos y, en última instancia, un mayor valor extraído del modelo.
- Control y personalización: Al tener tu propio modelo, tendrás control total sobre él, pudiendo ajustarlo y afinarlo según las necesidades específicas de tu empresa. Esto es ideal si requieres funcionalidades muy especializadas o si deseas integrar el modelo estrechamente con tus sistemas y flujos de trabajo existentes.
- Privacidad y seguridad de datos: Un gran problema al usar APIs externas es que debes enviar tus datos fuera de tu infraestructura, lo que podría generar preocupaciones de privacidad y seguridad. Con tu propio Llama 3, todos tus datos permanecen seguramente dentro de tus propios sistemas. Esto es crucial para empresas con requisitos estrictos de confidencialidad, como aquellas en las industrias de salud o finanzas.
- Participación en la comunidad de código abierto: Al alojar tu propio Llama 3, te conviertes en parte de la vibrante comunidad de código abierto que rodea al modelo. No solo estarás contribuyendo a un bien público, sino que también podrás beneficiarte de los consejos, trucos y mejoras compartidas por otros usuarios de Llama 3 en todo el mundo.
Además, con Meta anunciando actualizaciones futuras al modelo y el próximo lanzamiento de una versión de 400 mil millones de parámetros que rivaliza con GPT-4, alojar tu propio Llama 3 te posiciona bien para aprovechar rápidamente estos avances.
Una tercera vía: alojar Llama 3 en la nube
Existe una opción intermedia entre alojar Llama 3 internamente y utilizar una API externa: alojar el modelo en un servicio en la nube como Microsoft Azure o Google Cloud. Esta opción ofrece varios beneficios:
- Escalabilidad y mantenimiento simplificados: Al alojar Llama 3 en la nube, puedes aprovechar la infraestructura escalable y el mantenimiento proporcionado por el proveedor de la nube. Esto significa que no tienes que preocuparte por gestionar servidores físicos o lidiar con actualizaciones y parches de software.
- Costo optimizado: Los servicios en la nube a menudo ofrecen precios flexibles y basados en el uso, lo que significa que solo pagas por los recursos que realmente utilizas. Esto puede ser más rentable que mantener tu propia infraestructura, especialmente si tu uso del modelo es variable o impredecible.
- Seguridad y cumplimiento: Los principales proveedores de nube ofrecen robustas características de seguridad y cumplimiento, asegurando que tus datos y modelos estén protegidos de acuerdo con los más altos estándares de la industria. Esto puede simplificar enormemente el cumplimiento de regulaciones como GDPR o HIPAA.
- Fácil integración con otros servicios en la nube: Al alojar Llama 3 en la nube, puedes integrarlo fácilmente con otros servicios ofrecidos por el proveedor, como almacenamiento de datos, análisis o aplicaciones web. Esto puede permitir poderosos flujos de trabajo de IA de extremo a extremo completamente dentro del ecosistema de la nube.
Esta opción a diferencia de la anterior no te permite “fijar los costes”, pero es una alternativa interesante especialmente si aún no tienes muy claro qué uso vas a darle a la IA.
El principio de “lo suficientemente bueno”
Al decidir entre alojar tu propio modelo o usar una API, es crucial considerar el principio de “lo suficientemente bueno”. Para muchos casos de uso empresarial, es posible que no necesites el modelo de vanguardia más potente. Tener un Ferrari está muy bien, pero igual no lo necesites para ir a comprar el pan el domingo por la mañana. Si un modelo puede manejar de manera confiable tus tareas requeridas, podría no haber necesidad de actualizar constantemente al último y mejor modelo.
Aquí es donde Llama 3 brilla particularmente. Según los benchmarks, Llama 3 tiene un rendimiento comparable a Claude 3 Sonnet de Anthropic, que es un modelo muy consistente y capaz con un rendimiento superior a GPT-3.5. Esto indica que Llama 3 probablemente será capaz de manejar una amplia gama de tareas empresariales, desde atención al cliente hasta generación de contenido y análisis de datos.
Entonces, para muchas empresas, alojar su propio Llama 3 podría ofrecer el equilibrio perfecto: un modelo extremadamente capaz que puede manejar la mayoría de las tareas, combinado con los beneficios de control, personalización y costo fijo que viene con alojar tu propio modelo. Como dice un invitado en el podcast: “una vez que un modelo es lo suficientemente bueno para hacer esa tarea para ti, no necesitas un modelo mejor”.
Velocidad del modelo: Problema o ventaja
Un factor importante a considerar al elegir entre alojar Llama 3 y usar una API es la velocidad del modelo. Hacer un request a un gran modelo de lenguaje como Llama 3 70B es computacionalmente costoso, lo que puede resultar en una latencia notable entre enviar una consulta y recibir una respuesta.
Para consultas puntuales donde unos pocos segundos de retraso no son críticos, esto puede no ser un problema. Sin embargo, para aplicaciones en tiempo real o casos de uso que requieren respuestas casi instantáneas, como chatbots o sistemas integrados en el flujo de trabajo, incluso retrasos de unos pocos segundos pueden ser inaceptables.
Las APIs de empresas líderes como OpenAI y Anthropic a menudo ofrecen tiempos de respuesta más rápidos, ya que sus modelos se ejecutan en hardware optimizado y altamente eficiente. Sin embargo, incluso estas APIs no son instantáneas y pueden enfrentar retrasos durante períodos de alta demanda.
Aquí es donde los chips especializados de Groq pueden cambiar las reglas del juego para Llama 3. Estos chips están diseñados específicamente para acelerar las cargas de trabajo de IA, potencialmente permitiendo tiempos de inferencia mucho más rápidos para modelos como Llama 3. Aunque aún es pronto para evaluar completamente el impacto de Groq, podría desnivelar la balanza hacia los modelos abiertos, en términos de velocidad. Puedes comprobar la rapidez de las respustas con Groq y Llama 3 en https://groq.com/
Estimación de costos para alojar Llama 3
Quizás en este punto, ya hayas decidido que la mejor solución para ti es alojar Llama 3 70b localmente. La pregunta natural que te estarás haciendo es ¿cuánto me va a costar? Sin entrar en mucho detalle, te presento a continuación un presupuesto de una arquitectura que sería capaz de hacer inferencia sobre Llama 70b. Obviamente, lo más costoso son las GPUs:
- Procesador: 64 núcleos, 128 hilos, 3500€
- Placa base: 800€
- RAM: 192Gb necesarios, unos 500€
- GPU: 2x NVIDIA A100 unos 39000€ en total
- Otros componentes: 1000€
En total, calcula que necesitaras unos 45000€ para poder alojar una instancia de Llama 3 a su máxima capacidad. Si planeas realizar entrenamiento adicional (fine-tuning) en Llama 3, los requisitos de hardware serán aún mayores, por lo que es importante pensar si tu solución lo necesitará antes de hacer la inversión en la infraestructura.
Vale la pena señalar que se espera que pronto se lancen versiones cuantizadas de Llama 3, que podrían reducir significativamente los requisitos de memoria y permitir la inferencia en hardware más modesto. Sin embargo, ten en cuenta que estas versiones presentan una degradación en el rendimiento. De nuevo, evalúa de antemano si puedes permitirte dicha degradación en tu caso particular.
Para tomar una decisión informada sobre si acceder a modelos cerrados a través de una API, alojar tu propio modelo en un servidor local o en la nube, es fundamental realizar un análisis económico basado en el número de solicitudes (requests) que planeas hacer al mes, el tamaño medio del ‘prompt’ y del ‘output’ (en número de tokens), y los costos asociados a cada opción.
- Acceder a modelos cerrados mediante API
- Costo por token: OpenAI cobra aproximadamente 0.03€ por 1000 tokens para GPT-4 (texto), mientras que Anthropic cobra alrededor de 0.02€ por 1000 tokens.
- Costo estimado por request: Supongamos un promedio de 1500 tokens por consulta (1000 tokens de prompt y 500 tokens de respuesta).
- Costo por request:
- OpenAI GPT-4: 0.03€ * (1500 / 1000) = 0.045€
- Anthropic Claude 3 Opus: 0.02€ * (1500 / 1000) = 0.03€
Usaremos un promedio de 0.0375€ por request.
- Alojar el modelo en un servidor propio
- Costo inicial de infraestructura: Estimado en 45000€, según los precios mencionados anteriormente.
- Costo de mantenimiento mensual: Aproximadamente el 5% del costo inicial para mantenimiento y electricidad, es decir, unos 2500€ mensuales.
- Costo por request: Una vez cubiertos los costos iniciales, este costo es esencialmente fijo y depende del volumen de solicitudes. Supongamos un volumen de 1 millón de requests mensuales: 2500€ (mantenimiento) / 1.000.000 requests = 0.0025€ por request.
- Alojar el modelo en la nube
- Costo de infraestructura en la nube: Supongamos un costo mensual de 0.10€ por minuto para el uso de una instancia de GPU de alta capacidad.
- Uso estimado de GPU por request: Supongamos que cada request tarda unos 2 segundos en procesarse.
- Costo por request: (2 segundos / 60 segundos) * 0.10€ = 0.00333€
- Costo mensual adicional: Almacenamiento, administración y otros costos asociados. Se estima un costo adicional de 2000€ mensuales.
- Costo total por request: Supongamos 1 millón de requests mensuales: 2000€ / 1.000.000 requests = 0.002€ + 0.00333€ = 0.00533€ por request.
En la siguiente imagen puede verse una comparativa gráfica del costo total mensual en función del número de requests para cada opción.
La decisión entre las tres opciones depende en gran medida del volumen de solicitudes mensuales proyectadas:
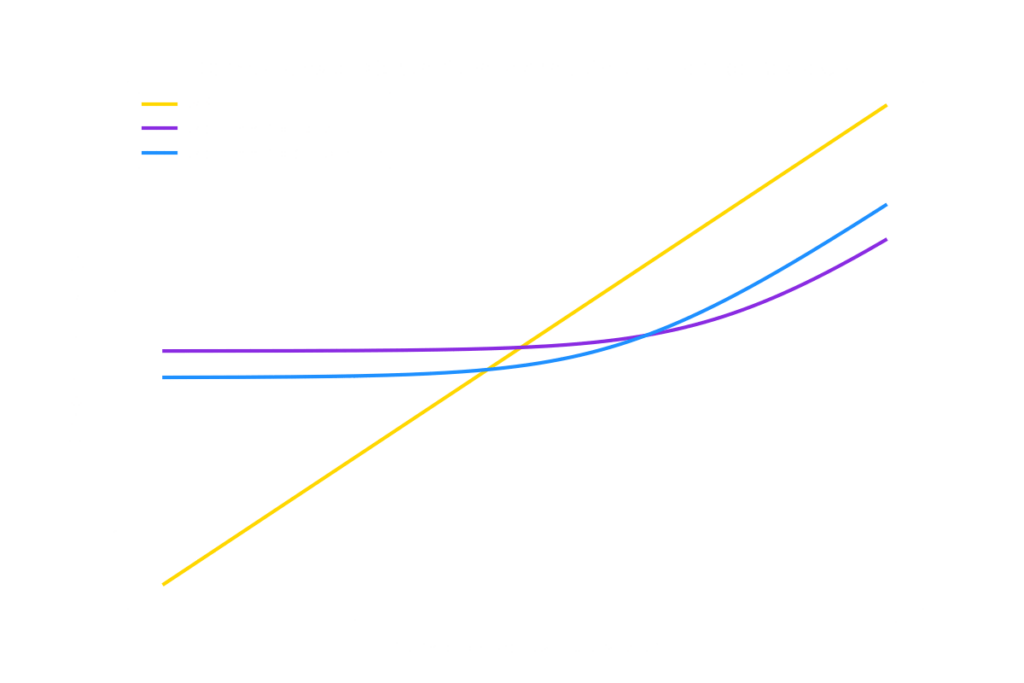
- API: Si se espera un volumen bajo de solicitudes (menos de 100,000 al mes), el uso de una API es la opción más conveniente debido a su facilidad de uso y rapidez de implementación.
- Alojamiento Local: Si se planea un uso intensivo de IA (más de 1 millón de solicitudes mensuales), alojar el modelo localmente reduce significativamente el costo por request e incrementa el control y la personalización.
- Alojamiento en la Nube: Ofrece un punto intermedio entre las dos opciones anteriores, siendo conveniente para volúmenes moderados de solicitudes (100,000 – 1 millón al mes) proporcionando escalabilidad y flexibilidad con costos razonables.
En última instancia, la elección adecuada dependerá de las necesidades, recursos y prioridades específicas de cada empresa, pero esta comparativa proporciona una guía inicial para tomar una decisión informada.
Conclusión
La decisión entre alojar tu propio modelo abierto como Llama 3 o utilizar modelos cerrados a través de API dependerá en última instancia de las necesidades, recursos y prioridades específicas de tu empresa. Alojar tu propio Llama 3 ofrece control, personalización y potencialmente menores costos a largo plazo, mientras que las APIs ofrecen facilidad de uso, escalabilidad y acceso a los modelos más recientes.
La opción de alojar Llama 3 en un servicio en la nube ofrece un atractivo término medio, combinando la personalización y el control de un modelo alojado internamente con la escalabilidad y la facilidad de mantenimiento de una API.
Independientemente de la ruta que elijas, el lanzamiento de Llama 3 marca un hito emocionante en la democratización de la IA. Con modelos altamente capaces ahora disponibles gratuitamente a través de código abierto, las barreras para la adopción empresarial de la IA son más bajas que nunca. Mientras que tecnologías innovadoras como los chips Groq prometen un rendimiento aún mayor para modelos como Llama 3 en el futuro.