
Introducción
En el ámbito del análisis de datos, la exploración y comprensión de un conjunto de datos es una de las primeras y más cruciales etapas. Cualquier buen científico de datos que se preste, antes de aplicar complejos modelos de IA, debe realizar un análisis exploratorio previo de los datos, para saber cuál es la naturaleza del material que tiene entre manos.
Hoy abordaremos el análisis de una base de datos de viviendas en Madrid utilizando la herramienta KNIME, que nos permitirá descubrir patrones y generar conclusiones valiosas. KNIME es una plataforma de análisis de datos de código abierto que facilita la creación de flujos de trabajo para análisis de datos y aprendizaje automático sin necesidad de programación. Por tanto, para seguir este post no necesitarás ningún conocimiento de programación
Planteamiento del problema
El objetivo de este análisis es comprender los factores clave que influyen en el precio de venta de las viviendas en Madrid. Este análisis será valioso para una empresa inmobiliaria que busca formular estrategias personalizadas para diferentes grupos de clientes.
Entender los datos
Lo primero que necesitamos es descargar la base de datos con la que vamos a trabajar. Se trata de una base de datos de viviendas de Madrid. Descárgala del siguiente enlace:
Ahora ya podemos abir nuestro dataset. Para esta etapa, podríamos simplemente usar Excel, importando el csv de forma tradicional. Pero, como vamos a usar KNIME para el resto del análisis, centraremos allí todo el proceso. Observa la Figura 1 y el texto que la acompaña para aprender a hacerlo.
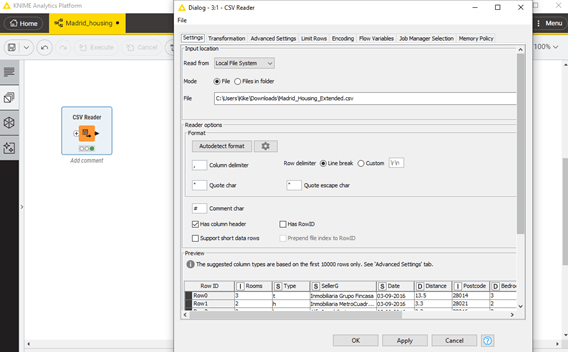
Figura 1. Importación de base de datos a KNIME. Nuestra base de datos, en este caso, se encuentra en un archivo externo .csv. Lo primero que necesitamos es crear un nuevo “Workflow” en nuestro “local space”. Podemos darle el nombre que queramos. Una vez creado, Debemos añadir el módulo de importación csv, llamado “CSV Reader” (buscarlo en la barra de búsqueda de la pestaña “Nodes”, a la izquierda de la pantalla). Para añadir el nodo, basta con arrástralo a la ventana principal. Depués debemos configurar el nodo, apuntando al archivo de nuestra base de datos: “Madrid_Housing.csv”. Por último, haz clic en OK y después haz clic en “Ejecutar” (botón con el símbolo “play”) en el nodo que acabas de insertar.
El dataset de viviendas en Madrid contiene 27,114 filas y 15 columnas. Cada fila representa una vivienda y las columnas incluyen detalles estructurales y geográficos, como el agente inmobiliario, la fecha de venta, el año de construcción y el precio de la vivienda.
Atributos del Dataset:
- Rooms: Número de habitaciones en la casa
- Type: Este es el tipo de casa, como casa, cabaña, villa, casa adosada, etc.
- SellerG: Nombre del agente inmobiliario que vendió la propiedad
- Date: Fecha en la que se vendió la propiedad
- Distance: Distancia de la propiedad desde el Distrito Central de Negocios (CBD) en kilómetros
- Postcode: Código postal del área
- Propertycount: Número de propiedades que están presentes en el suburbio
- Regionname: Nombre de la región en la que se encuentra la propiedad
- BuildingArea: Área construida en metros cuadrados
- Bedroom: Número de dormitorios en la casa
- Bathroom: Número de baños en la casa
- Car: Número de espacios de estacionamiento en la propiedad
- LandSize: Tamaño del terreno en metros cuadrados
- YearBuilt: Año en el que se construyó la casa
- Price: Precio de venta de la casa en dólares australianos (AUD)
En ciencia de datos, este es el formato habitual para casi todos los problemas: los datos vienen organizados siempre de la misma forma, en datatables de este tipo. Sea cual sea la plataforma que utilizas (Python, KNIME, etc.) siempre tendrás la opción de importar datos organizados de esta forma. Recuerda:
- Cada fila es una observación (sample), un dato o muestra a considerar
- Cada columna es un atributo (feature), una característica que define de alguna forma la observación considerada.
Preparación de los Datos en KNIME
El paso de preparación de datos es siempre el primero en todo proceso de construcción de un modelo ML. La razón es que la naturaleza de cada es distinta, por lo que la capacidad de automatizar el proceso es limitada: en una base de datos puede ser necesario transformar el tipo de variable de la columna “Precio” para pasar todas las cantidades monetarias a euros, pero en otra base de datos lo que puede ser necesario es cambiar el separador decimal de toda la base de datos de coma a punto, y eliminar los valores perdidos. Estas particularidades hacen que cada caso sea distinto y que, para realizar un buen análisis, sea recomendable comenzar con una exploración visual de la base de datos.
Vamos a ver en qué consiste este paso en nuestro caso de estudio. Si echamos un ojo a la columna “BuildingArea”, veremos que KNIME piensa que esta debe ser una variable tipo “string”, es decir, una cadena de caracteres, en lugar de un número, que es lo que nos imaginaríamos para la superficie de una vivienda. KNIME intenta “adivinar” el tipo de las distintas variables observando los distintos valores que presentan. ¡La razón de que falle en este caso es que dicha variable de hecho contiene varios valores no numéricos! Quien haya elaborado la base de datos (o el programa que la haya generado) a usado la palabra “missing” en varias entradas, para indicar la ausencia de ese dato. Hubiera habido mejores formas de hacer eso, pero ya es tarde para nosotros.
Lo que podemos hacer es cambiar el tipo de la variable para que sea numérica, y tratar los valores perdidos de forma apropiada. Para hacerlo, vamos a insertar un nodo de transformación llamado “String to Number”. El nombre es autoexplicativo: después de este nodo los datos de la columna “BuildingArea” pasarán a ser números enteros. Consulta la Figura 2. para más detalles.
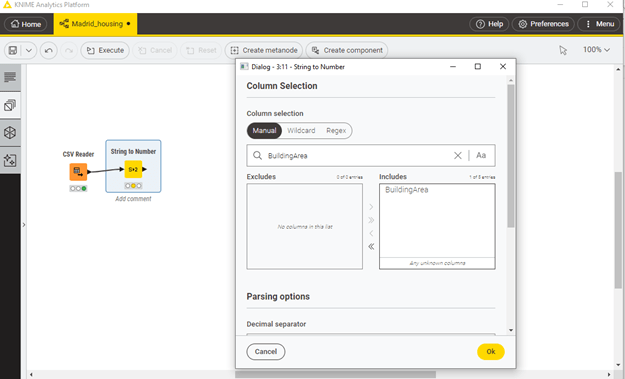
Figura 2. Conversión de tipo con el nodo “String to Number”. Tras insertarlo y unirle a la salida del nodo “CSV Reader”, debemos configurarlo haciendo doble clic sobre su icono. En la ventana de configuración, debemos seleccionar la columna a filtrar (“BuildingArea”) y a continuación el tipo deseado (en este caso, Integer, porque queremos que sean valores enteros. Tras hacer click en “Ok” y ejecutar el nodo, ya tendremos la columna modificada con el tipo apropiado.
Aún no hemos terminado la fase de limpieza. Para nuestro primer estudio, necesitaremos aislar las observaciones de la base de datos que estén completas, es decir, que no tengan ningún valor perdido en ninguna de sus features. Para ello, insertaremos un nuevo nodo llamado “Missing Value” que tratará los valores perdidos de forma apropiada (en este caso, eliminando la fila correspondiente). Consulta la Figura 3 para más detalles. Una vez insertado, configurado y ejecutado el nodo, podemos ver que el tamaño de la base de datos en este punto se ha reducido considerablemente: solo conservamos 8682 entradas.
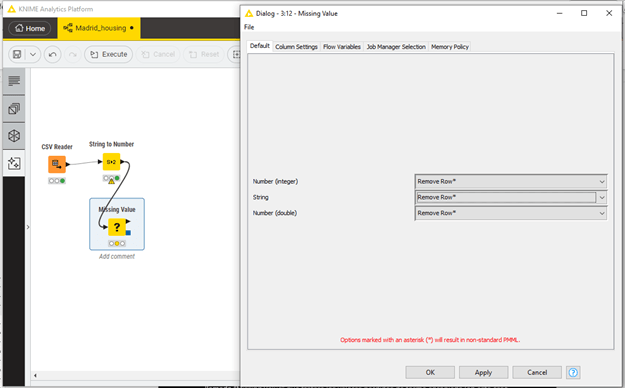
Figura 3. Tratamiento de valores perdidos con el nodo “Missing Value”. Con él, nos aseguraremos que solo se mantienen en la base de datos las observaciones que no tengan ningún valor perdido en ninguna de sus features (es decir, conservamos solo las filas que estén completas). Depende el tipo de análisis que vaya a realizarse, este paso quizás pueda obviarse y así retener una base de datos de mayor tamaño. Dependerá del caso. Ten en cuenta también que, aunque después de este nodo nuestra base de datos habrá sufrido una reducción significativa, siempre podremos seguir accediendo a la base de datos completa, ya que esta no se elimina. Una vez insertado el nodo y conectado al flujo anterior, hacemos doble clic para configurarlo. En este caso, seleccionamos “Remove Row” para todos los tipos de datos, pues queremos eliminar la correspondiente fila si cualquiera de sus features es inválida. Ahora hacemos clic en “Ok” y ejecutamos el nodo.
Análisis Exploratorio de Datos: Caso Univariante
Comencemos con un análisis individual de cada feature. Es decir, todavía no vamos a buscar relaciones entre distintas columnas. El análisis univariante nos permite examinar cada variable individualmente para comprender su distribución y características.
Vamos a insertar un nodo de visualización en nuestro workflow: el nodo “Statistics View”. Allí podemos ver un sencillo análisis univariante de nuestra base de datos. Después de insertarlo, conectarlo y ejecutarlo, podemos hacer doble clic sobre su icono para acceder a la vista de visualización de estadísticas. En ella podemos ver, por filas, las distintas features, y por columnas, estadísticas descriptivas de cada una de ellas: valor medio, valores máximos, percentiles, valores más habituales, etc. Este resumen en muy valioso para entender la naturaleza de nuestra base de datos y extraer las primeras conclusiones.
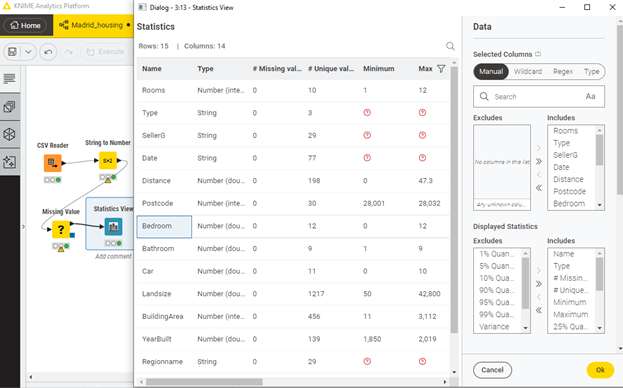
Figura 4. Vista del nodo “Statistics View”, una vez insertado, conectado y ejecutado. Podemos usar esta vista para extraer las primeras conclusiones importantes sobre nuestros datos: valores máximos y mínimos de cada variable, valores más habituales, etc. En esta vista, a diferencia de las anteriores, tenemos por filas las distintas features de la base de datos, y por columnas distintos estadísticas descriptivas de cada variable.
Fijémonos por ejemplo en la fila “Bedroom”. Allí podemos ver que el número de habitaciones en la base de datos va desde 0 hasta 12: ¡parece que contiene pisos realmente grandes! También podemos ver que la media de habitaciones es 3.079, lo cual tiene sentido y refuerza que pensemos que nuestro workflow hasta este punto es correcto (si hubiésemos obtenido aquí un valor de p.ej. 57, deberíamos empezar a pensar en revisar lo que hemos hecho).
Si echamos ahora un ojo a las features “Landsize” y “BuildingArea” podemos ver la distribución de superficie del terreno y de la propia vivienda, respectivamente. Por ejemplo, la superficie del terreno varía desde 50m2 hasta 42,800m2. Parece que hay terrenos realmente extensos, pero representan una minoría de la muestra (son outliers) ya que, por ejemplo, el percentil 75 es 181m2, lo que indica que el 75% de los pisos tienen 181m2 o menos. En la fila correspondiente a “BuildingArea” podemos ver valores análogos; ten en cuenta que no hubiésemos podido ver la información de esta feature si no hubiésemos hecho la conversión de tipo que hicimos en la fase de preprocesado.
Observemos ahora la feature “distance”, que mide la distancia desde la propiedad al Distrito Central de Negocios (las Cuatro Torres). La propiedad más alejada está a 50km, pero la media es de unos 11km, lo que pone de manifiesto que la mayoría de las viviendas de esta base de datos están relativamente cerca. El mínimo es de 0km, por lo que hay alguna vivienda del mismo Centro de Negocios.
Fijémonos ahora en la fila “Type”. Puede observarse que la mayoría de valores no se muestran. La razón es que la variable “type” es de tipo “string”, es decir, los valores que encontramos en esta columna el la base de datos son “palabras”, y no números, por lo que por ejemplo el concepto de “media” no tiene sentido aquí. Sin embargo, si que podemos ver el valor más frecuente (llamado “moda”) en la columna “10 most frequent values”. El tipo de vivienda más habitual es el tipo “h”, que corresponde con “house” (casa).
Hay más información interesante: podemos ver que la base de datos contiene pisos construidos después de 1850 (valor mínimo de la feature “YearBuilt”). Respecto a los precios de venta, la feature “Price” informa de que, como era de esperar, el rango de variación es muy grande, ¡con un valor máximo de 9 millones de euros!
Conclusiones y presentación
Terminamos presentando las principales conclusiones encontradas en el análisis anterior:
- Un gran número de entradas de la base de datos están incompletas. Más concretamente, menos de un tercio de toda la base de datos inicial ha sido finalmente utilizada para el estudio final. Esto puede poner de manifiesto algún problema en la etapa de recogida de datos. Se recomendaría revisar el sistema de adquisición para evitar problemas en el futuro.
- La media de habitaciones por vivienda es aproximadamente 3, lo cual es razonable para la distribución de viviendas en Madrid. Esto sugiere que el procesamiento de datos realizado hasta ahora es correcto.
- La superficie del terreno (“Landsize”) varía significativamente, con un valor mínimo de 50 m² y un máximo de 42,800 m². Esto indica la presencia de outliers, ya que la mayoría de las viviendas tienen una superficie de terreno considerablemente menor.
- La distancia desde las viviendas al Distrito Central de Negocios (CBD) varía de 0 a 50 km, con una media de 11 km. Esto muestra que la mayoría de las viviendas están relativamente cerca del centro de la ciudad.
- La mayoría de las viviendas en la base de datos son del tipo “house” (casa), lo que se refleja en la moda de la columna “Type”.
- El rango de los precios de venta es muy amplio, con un precio máximo de 9 millones de euros. Esto destaca la variabilidad del mercado inmobiliario en Madrid y sugiere la necesidad de segmentar los datos para análisis más detallados.
- La antigüedad de las viviendas es también muy variada, con algunas construidas después de 1850. Este dato es relevante para estudios históricos y de conservación del patrimonio arquitectónico en Madrid.
En conclusión, el análisis exploratorio de la base de datos de viviendas en Madrid nos ha proporcionado una visión general de los datos y ha identificado varios patrones clave que influencian el mercado inmobiliario. Este estudio inicial sienta las bases para análisis más profundos y detallados. En un próximo post, continuaremos explorando esta base de datos con un análisis bivariante, para investigar las relaciones entre diferentes variables y obtener insights adicionales. ¡Hasta entonces!